本文用于介绍引用和指针的传递值和返回值问题,其中包括函数的值传递和引用传递、直接返回值和引用作为函数的返回值、返回函数内部new分配的内存的引用和引用。
函数的值传递和引用传递
本部分参考自:https://www.cnblogs.com/zjutzz/p/6818799.html
C++的函数参数传递方式,可以是传值方式,也可以是传引用方式。传值的本质是:形参是实参的一份复制。传引用的本质是:形参和实参是同一个东西。
传值和传引用,对大多数常见类型都是适用的(就我所知)。指针、数组,它们都是数据类型的一种,没啥特殊的,因此指针作为函数参数传递时,也区分为传值和传引用两种方式。
例如:
1 | void fun_1(int a); //int类型,传值(复制产生新变量) |
如果希望通过将参数传递到函数中,进而改变变量的值(比如变量是T a,T表示类型),则可以有这2种方式选择:
- 传a的引用:
void myfun(T& a) - 传a的地址的值:
void myfun(T* a)
传值方式
这是最简单的方式。形参意思是被调用函数的参数/变量,实参意思是主调函数中放到括号中的参数/变量。传值方式下,形参是实参的拷贝:重新建立了变量,变量取值和实参一样。
写一段测试代码,并配合gdb查看:
1 |
|
1 | ➜ hello-cpp git:(master) ✗ g++ -g test.cc |
可以看到,实参x和y的值为1和2,形参a和b的值都是1和2;而x与a的地址、y与b的地址,并不相同,表明形参a和b是新建里的变量,也即实参是从形参复制了一份。这就是所谓的传值。
传指针?其实还是传值!
1 |
|
1 | ➜ hello-cpp git:(master) ✗ g++ -g test2.cc |
可以看到,main()函数内和test()函数内,变量p的值都是0,也就是都是空指针;但是它们的地址是不同的。也就是说,形参p只是从形参p那里复制了一份值(空指针的取值),形参是新创建的变量。
1 | ➜ hello-cpp git:(master) ✗ ./a.out |
传引用
传值是C和C++都能用的方式。传引用则是C++比C所不同的地方。传引用,传递的是实参本身,而不是实参的一个拷贝,形参的修改就是实参的修改。相比于传值,传引用的好处是省去了复制,节约了空间和时间。假如不希望修改变量的值,那么请选择传值而不是传引用。
1 |
|
1 | ➜ hello-cpp git:(master) ✗ ./a.out |
显然,形参a和实参a完全一样:值相同,地址也相同。说明形参不是实参的拷贝,而是就是实参本身。
实现swap()函数
1 |
|
程序执行结果:
1 | originally |
真的理解了吗?
其实出问题最多的还是指针相关的东西。指针作为值传递是怎样用的?指针作为引用传递又是怎样用的?
首先要明确,“引用”类型变量的声明方式:变量类型 & 变量名。
“指针”类型的声明方式:基类型* 变量名。
所以,“指针的引用类型”应当这样声明:基类型*& 变量名。
这样看下来,不要把指针类型看得那么神奇,而是把它看成一种数据类型,那么事情就简单了:指针类型,也是有传值、传引用两种函数传参方式的。
指针的传值
1 | void myfun(int* a, int n) |
指针的传引用
1 | void myfun(int*& arr, int n) |
使用函数模版
考虑这样一个问题:写一个函数,遍历输出一个一维数组的各个元素。
第一种方法,数组退化为指针,传值。同时还需要另一个参数来指定数组长度:
1 | void traverse_1d_array(int* arr, int n){ |
缺点是需要指定n的大小。以及,传值会产生复制,如果大量执行这个函数会影响性能。
另一种方式,传入参数是数组的引用。想到的写法,需要事先知道数组长度:
1 | void traverse_1d_array(int (&arr)[10]){ |
缺点是需要在函数声明的时候就确定好数组的长度。这很受限。
还有一种方法。使用模板函数,来接受任意长度的数组:
1 | template <size_t size> |
这种使用模板声明数组长度的方式很方便,当调用函数时,编译器从数组实参计算出数组长度。也就是说,不用手工指定数组长度,让编译器自己去判断。这很方便啊。用这种方式,随手写一个2维数组的遍历输出函数:
1 | template<size_t m, size_t n> |
总结
普通类型,以int a为例:
1 | void myfun(int a) //传值,产生复制 |
指针类型,以int* a为例:
1 | void myfun(int* a) //传值,产生复制 |
数组类型,以int a[10]为例:
1 | void myfun(int a[], int n) //传值,产生复制 |
返回值和返回引用
本部分参考:
[1] https://blog.csdn.net/weixin_40539125/article/details/81410008#commentBox
[2] https://www.cnblogs.com/fly1988happy/archive/2011/12/14/2286908.html
[3] https://www.cnblogs.com/duwenxing/p/7421100.html
引用作为返回值:
语法:类型 &函数名(形参列表){ 函数体 }
1 |
|
case 1:用返回值方式调用函数
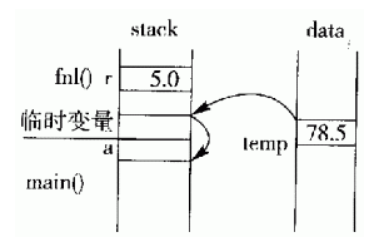
返回全局变量temp的值时,C++会在内存中创建临时变量并将temp的值拷贝给该临时变量。当返回到主函数main后,赋值语句a=fn1(5.0)会把临时变量的值再拷贝给变量a
case 2:用函数的返回值初始化引用的方式调用函数
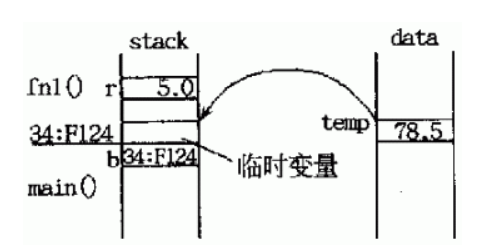
这种情况下,函数fn1()是以值方式返回到,返回时,首先拷贝temp的值给临时变量。返回到主函数后,用临时变量来初始化引用变量b,使得b成为该临时变量到的别名。由于临时变量的作用域短暂(在C++标准中,临时变量或对象的生命周期在一个完整的语句表达式结束后便宣告结束,也就是在语句float &b=fn1(5.0);之后) ,所以b面临无效的危险,很有可能以后的值是个无法确定的值。
如果真的希望用函数的返回值来初始化一个引用,应当先创建一个变量,将函数的返回值赋给这个变量,然后再用该变量来初始化引用:
1 | int x=fn1(5.0); |
case 3:用返回引用的方式调用函数
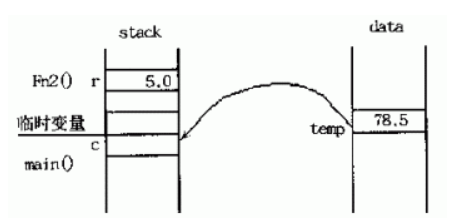
这种情况下,函数fn2()的返回值不产生副本,而是直接将变量temp返回给主函数,即主函数的赋值语句中的左值是直接从变量temp中拷贝而来(也就是说c只是变量temp的一个拷贝而非别名) ,这样就避免了临时变量的产生。尤其当变量temp是一个用户自定义的类的对象时,这样还避免了调用类中的拷贝构造函数在内存中创建临时对象的过程,提高了程序的时间和空间的使用效率。
case 4:用函数返回的引用作为新引用的初始化值的方式来调用函数
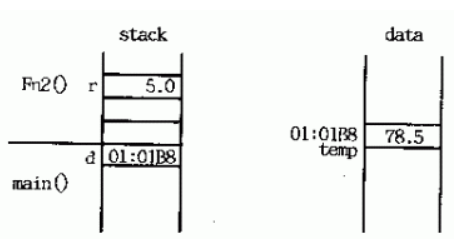
这种情况下,函数fn2()的返回值不产生副本,而是直接将变量temp返回给主函数。在主函数中,一个引用声明d用该返回值初始化,也就是说此时d成为变量temp的别名。由于temp是全局变量,所以在d的有效期内temp始终保持有效,故这种做法是安全的。
注意几点!!!
1.引用作为函数的返回值时,必须在定义函数时在函数名前将&
2.用引用作函数的返回值的最大的好处是在内存中不产生返回值的副本
3.不能返回局部变量的引用。如上面的例子,如果temp是局部变量,那么它会在函数返回后被销毁,此时对temp的引用就会成为“无所指”的引用,程序会进入未知状态。
具体参见:https://bbs.csdn.net/topics/350254894
4.不能返回函数内部通过new分配的内存的引用。虽然不存在局部变量的被动销毁问题,但如果被返回的函数的引用只是作为一个临时变量出现,而没有将其赋值给一个实际的变量,那么就可能造成这个引用所指向的空间(有new分配)无法释放的情况(由于没有具体的变量名,故无法用delete手动释放该内存),从而造成内存泄漏。因此应当避免这种情况的发生
5.当返回类成员的引用时,最好是const引用。这样可以避免在无意的情况下破坏该类的成员。
具体参见:https://blog.csdn.net/dearwind153/article/details/51926746
6.可以用函数返回的引用作为赋值表达式中的左值
1 |
|
用引用实现多态
在C++中,引用是除了指针外另一个可以产生多态效果的手段。也就是说一个基类的引用可以用来绑定其派生类的实例
1 | class Father;//基类(父类) |
特别注意:
ptr只能用来访问派生类对象中从基类继承下来的成员。如果基类(类Father)中定义的有虚函数,那么就可以通过在派生类(类Son)中重写这个虚函数来实现类的多态。
常引用
常引用不允许通过该引用对其所绑定的变量或对象进行修改
1 |
|
1 |
|
这是由于func1()和“Tomwenxing”都会在系统中产生一个临时对象(string对象)来存储它们,而在C++中所有的临时对象都是const类型的,而上面的程序试图将const对象赋值给非const对象,这必然会使程序报错。如果在函数func2的参数前添加const,则程序便可正常运行了
关于返回函数内部new分配的内存的引用
1 | string& foo() |
非法的,为什么?
其实,不能说这是非法的,只能说这种u编程习惯很不好,这样很可能造成内存泄露。
1 | struct a_s |
如果按照以上两种做法,即使很小心的程序员也难免会造成内存泄露。
比如:string str = foo(); 显然new生成的这块内存将无法释放。
只能这样:
string& tmp = foo();
string str = tmp;
delete &tmp;
参考:https://blog.csdn.net/why_ny/article/details/7901670
引用返回值为需要传入的引用的对象
1 | //正确的方式 |
1 | //错误的方式 |
1 | //两种调用方式 |
返回const类型
由于返回值直接指向了一个生命期尚未结束的变量,因此,对于函数返回值(或者称为函数结果)本身的任何操作,都在实际上,是对那个变量的操作,这就是引入const类型的返回的意义。当使用了const关键字后,即意味着函数的返回值不能立即得到修改!如下代码,将无法编译通过,这就是因为返回值立即进行了++操作(相当于对变量z进行了++操作),而这对于该函数而言,是不允许的。如果去掉const,再行编译,则可以获得通过,并且打印形成z = 7的结果。
1 | include <iostream> |
1 |
|
拷贝构造与引用
看下面的函数,返回的是t而不是&t,所以一定会有临时变量产生。
1 | T function1(){ |
这里的过程是:
1.创建命名对象t
2.拷贝构造一个无名的临时对象,并返回这个临时对象
3.由临时对象拷贝构造对象x
4.T x=function1();这句语句结束时,析构临时对象
这里一共生成了3个对象,一个命名对象t,一个临时对象作为返回值,一个命名对象x。
下面的函数稍微复杂一定,它没有先定义一个中间变量t,看起来似乎是直接返回了一个临时变量。但实际上,如果不经过c++的优化,那么它并没有提高效率,因为它还是创建了3个对象。
1 | T function2(){ |
这里的过程是:
1.创建一个无名对象
2.由无名对象拷贝构造一个无名的临时对象
3.析构无名对象,返回临时对象
4.由临时对象拷贝构造对象x
5.T x=function2()语句结束时,析构临时对象。
这里一共生成了3个对象,其中有2个对象都是马上被析构掉的,不能被后面的代码使用。既然是这样,那么就会有优化的余地,可以尝试着不要前面的两个临时变量。c++确实会做这样的优化,优化后的c++会避免匿名对象和临时对象这两个对象的生成,而直接生成x,这样就减少了两次对象生成-回收的消耗,提高了程序性能。
其实function1()这段代码也是会经过优化的,但因为临时对象t是一个命名对象,所以一定会被创建。存储返回值的临时对象是多余的,会被优化掉而不生成。
但是,程序员不应该依赖这种优化,因为c++不保证这种优化一定会做。

